
I’ve decided to start writing more about audio because I’m endlessly fascinated by the whole thing and it helps me to cement my own knowledge in what I do in producing Cosmograf records and for other artists.
Every day is school day and I kind of think it is a responsibility to have some answers for those people that do see me as having some knowledge and expertise in this area. I’m also interested in the misunderstandings that a lot of people seem to have about audio particularly in the area of playback and the myth and legend that seems to come up when people start banding around file formats, bit depths and sample rates and maybe not understanding what those numbers mean. I don’t want to start a war with audiophiles, as we are very much on the same side in terms of caring about audio quality, but I do think there’s a clear disconnect between what we do in the studio and what people think we do in reference to what they hear on their hi-fi systems.
So here is Part1: Your Ears
Human hearing has been well studied and the frequency response and capabilities of the human ear are well understood by scientists, the medical profession and audio engineers alike. Your ears can hear frequencies between 20Hz and 20kHz. The curve is shaped like a smile with the mid frequencies being the easiest to detect and high and low frequencies needing to be much louder to have the same apparent volume to the listener. The threshold of hearing is 0db representing the absolute quietest sound that can be heard with easiest heard frequencies being around 2kHz. It’s no accident that our ears are most responsive between 300Hz and 3500Hz, for this is where the frequencies of human speech reside. Our ears have evolved in line with our need and abilities to communicate.
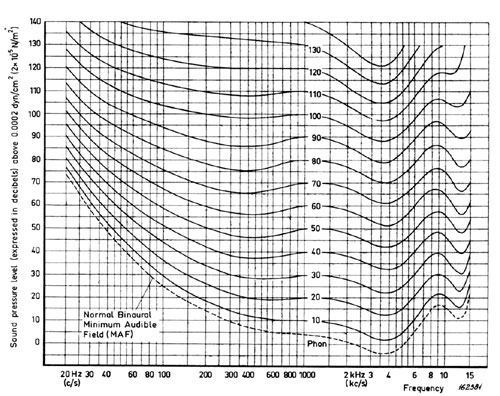
As we age our ability to hear high frequencies will markedly decrease. By the time you reach 35 you will have lost 11db worth of sensitivity at 8kHz and when you get to the age of a typical progressive rock fan demographic, 55-65, we can’t really hear any frequencies over 14kHz. It sounds terrible doesn’t it?, but the good news is that there is plenty left in the music that we can enjoy. Distortion, stereo perception and other modulating factors in the audio can still be appreciated. In fact the loss of these higher frequencies makes very little difference to the perception of music or audio quality at all. During my own experiments with EQ during mixing, I’ve found that if I cut all frequencies above 15kHz there’s very little perceptible difference in the audio.
All this is the subject of much irony of course when you factor in that our typical older music fan demographic is the worst for claims about their ability to detect the differences between the various ‘super aural’ file formats. Teenagers it seems are much less obsessed with audio quality despite being far better equipped to enjoy it. It reminds me of the famous phrase I recycled for ‘When Age Has Done Its Duty’. ‘The Energy of Youth is wasted on the young’ . As with everything though there’s a bit more to stuff sounding good than the content of your audio having all the frequencies from 20Hz to 20kHz and the younger among us tend to be a bit more switched on to some of those factors. We’ll get on to that in a later instalment.
So on the basis that it’s fairly clear that we can’t hear a damn thing below 20Hz and above 20kHz, it’s no surprise that much of the audio equipment we use to record and to playback works within these same frequency limits.
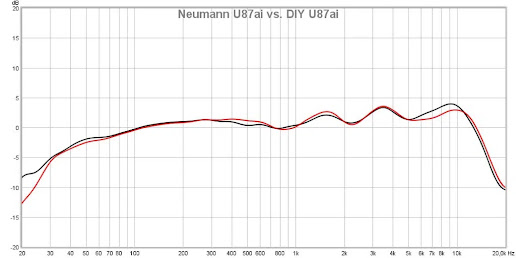
Let’s take a look at the typical frequency response of a much revered industry standard microphone, the Neumann U87.

Yep you guessed it, it’s pretty much an upside version of our hearing response curve. So the clever engineers of Neumann basically came up with a physical device that converts sound into an electrical signal and at the other end of the chain, someone made some speakers that convert that amplified signal back to sound again that we can hear. You might consider that the best possible reproduction of that sound would be a completely flat response from 20hz to 20kHz and then back again on playback. Sadly life and physics isn’t that simple and we need to design microphone capsules and accompanying amplifier designs to convert that signal into something we hear. That’s not as exact as it might be and as you can see the ripples in the Neumann u87 graph shows a bump at around 3500Hz and again at 10KHz. Experienced audio engineers have learned these characteristics and those with golden ears and can actually hear the particular sound characteristic of this microphone. Every microphone design has its own signature, a function of physical size of the capsule, and the design of the amplifier circuit that converts the signal.
In the studio, each microphone is connected to a microphone pre-amplifier (pre-amp) or ‘mic pre’ as they are known to boost the tiny signal into something we can record. Again this will have its own characteristic. Take a look at another studio classic the Neve 1073.
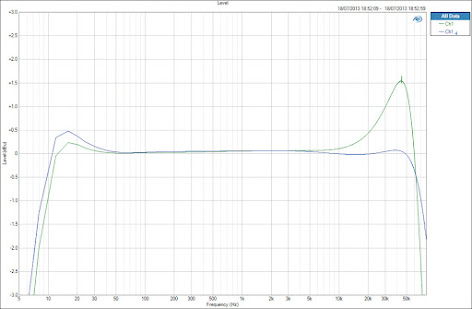
Now the response curve is much wider. The amplifier is not constrained by the physics of converting sound energy into electrical energy and has the ‘easier’ task of converting a small electrical signal into a larger one. This enables it to have a much larger frequency response from 10Hz up to 50kHz and more. You’ll notice this also has some odd bumps. The large one is at 75kHz are the resonances caused by the transformer design. The important consideration here is the curve from 20Hz to 20kHz is almost entirely flat, a facet of great amplifier design. Audio engineers quickly discovered that the interaction between microphones and preamps, and the relationship of gain between input and output stages created more interesting curves and elements of distortion and signal phase became important characteristics that influenced the sound. We sometimes use these characteristics to imbue ‘colour’ to the sound being recorded. An expert engineer can decide what microphone is best suited to the range and power of a vocalist and what pre-amp will present that sound in the best way. Do we want clarity, or warmth?
For the first time in our examination of audio we are exploring the possibility that perfect reproduction is not as desirable as we think it is. In fact it’s this colour that gives recorded music a lot of its distinctive and memorable sound signature. You’ll hear some artists say that they love a particular studio because of ‘the sound of the desk’. It’s the preamps in the console that give it this flavour and contrary to popular opinion, we can use the same old school tech in a modern recording studio and even simulate some of it with plug ins.
Following from the pre amp stage we then send it to our recording medium. In the old days it would be tape but these days we use Digital Audio workstations (DAW) and audio interfaces that capture the analogue audio and convert it to digital so we can process it. We’ll go back to that process another time.
For now let’s just finish the audio chain by thinking of speakers. Once our music is recorded we will need to play it back and surprise, surprise the speakers we use in the studio will broadly have similar frequency characteristics to the microphone.
Enter the Yamaha NS10. The NS10 was originally designed as a hifi speaker back in 1978 but it quickly faded into obscurity. The story of how a pair ended up being on just about every meter bridge in every major recording studio is somewhat filled with folklore and largely attributed to the work of Bob Clearmountain, but the main thrust is that some bright spark realised that hifi’s loss was the studio engineer’s gain, and would result in one of the most capable near field monitors ever being produced.
The beauty of the NS10 is that the frequency response is an inversion of own hearing capability. There’s a steep roll off on the bass and similarly at higher frequencies. In other words the speaker accentuates and reveals the mid range where everything happens. Coupled with this, the NS10 had extraordinary capabilities in representing frequencies with the minimum of time delay, known technically as group delay, actually the phase change with frequency expressed as time.

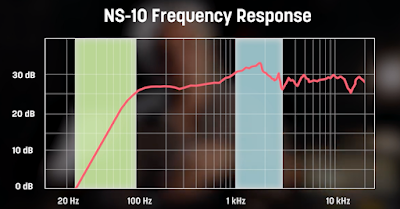
As you can see though, the flip side of the design is there’s very little bass response in the bass and the curve is almost the opposite of what a typical retailed hifi speaker will be, that will accentuate the bass and higher frequencies to overcome the limitations of our own hearing.
Well as you might expect the NS10s sound bloody awful and it’s no wonder they failed as a hifi speaker. I have a set in my studio and the sound is markedly improved with the additional of a sub-woofer to fill in the bottom end but the purpose of these really is to reveal the detail in the mid range where the critical mix decisions are made.
One thing that does amuse me is when I hear audiophiles talk about wishing to hear the music as it is played back in the studio. I think they’d be pretty shocked how bad that sounds in some cases. Luckily most studios, as I do, will also have a set of full range monitors that provide a much more fulfilling listen, but even then it’s not true that the music will sound best in the studio at all.
If we’ve done our job correctly it will probably sound better on high end hifi systems and just as good on fairly middle of the road gear. This is the difference between accurate representation of the recorded material and putting it all together as a cohesive ‘mix’ that will sound great on your system.
I’ll explore some of the techniques we use to do that in more detail in another episode.